
- Wed 09 September 2020
- Data Science
- #neo4j
Introduction
On September 11, 1973, Chile faced a military coup lead by Augusto Pinochet and the US agenda. Pinochet would be then dictator and leader of the military regime until 1989. During the regime, thousands of people were kidnapped, tortured and killed. The atrocities committed by the regime are a scar that defines what Chile is today, and there are families that are still looking for clues to find their missing relatives. "Nostalgia for the light" is a relevant documentary portraying people looking for their relatives, comparing it to the way astronomers look for stars in the sky.
As part of the efforts to shed light on the truth about what happened, two official reports can be noted:
- The first one was issued under the presidency of Patricio Alwyin in the year 1991, shortly after the military dictatorship ended. This document is known as the Rettig Report.
- The second report was issued during the first presidency of Michelle Bachelet, and it attempts to extend these efforts in what is known as the Valech Report.
It came to my knowledge that some people, more specifically, Danilo Freire and others, published a dataset and an article containing the information about the 903 pages of the report, along with a Github repository.
Freire, Danilo, David Skarbek, John Meadowcroft, and Eugenia Guerrero. 2019. “Deaths and Disappearances in the Pinochet Regime: A New Dataset.” SocArXiv. May 31. doi:10.31235/osf.io/vqnwu.
From the article that goes with the dataset,
Although the (Rettig) Report is a valuable source of information for scholars, quantitative researchers cannot readily use the rich data it contains. In this paper, we present a manually-coded dataset with all information from the Truth Commission Report plus new variables we collected to complement the original records. We transcribed every personal detail from the 903 pages of the English translation of the Report, assigned a unique identification number to each victim, then georeferenced the location of the human rights abuses. We added coordinates of latitude and longitude to every location mentioned in the report, such as places used to torture, interrogate or murder the victims.
The repository explains this better
This Github repository contains data and documented R code for Deaths and Disappearances in the Pinochet Regime: A New Dataset by Freire et al (2019). We coded the personal details of 2,398 victims named in the Chilean Truth Commission Report along with information about the perpetrators and geographical coordinates for all identifiable atrocity locations. The dataset covers from 1973 to 1990 and includes 59 indicators. Please refer to our accompanying article and our online appendix for more details.
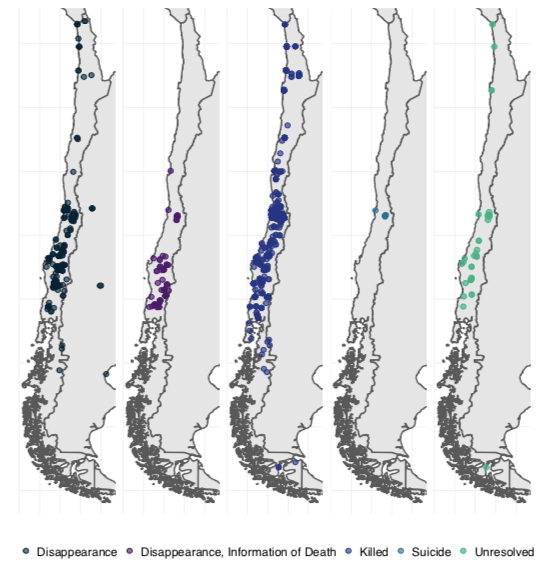
map of events from the pinochet repository
I wanted to model this dataset as a graph, with the intention to explore the data as what it is, a network that links victims to places and events. This an attempt to learn and to remember.
Roadmap
I will be first modeling the dataset as graph, using neo4j and py2neo. I will be using docker, as always. Next I will serve this graph using graphql through python's graphene library (although I recommend using apollo.js instead), and finally I will consume this service using a leaflet.js map.
I have other ideas, but I have to finish what I have right now. I would like to link this data to other information related to this dataset (e.g. the Valech report and the Londres 38 site, which we will see later on), perhaps through the graphql layer, or maybe using a semantic model and tools like ontop and protege. I learnt about these technologies the past semester and I've been itching to use them in something interesting.
Before starting
Tabular form data exploration
You can see an analysis of the data in tabular form using Pandas and a rudimentary map implementation using folium, in this notebook.
The notebooks is as of now in spanish only, and it will take a while to translate it. You can also see the analysis done in R in the original repository!
Related tutorials
I've used these tutorials up to some extent. Please check them if you wish to have more code examples!
- https://github.com/neo4j-examples/neo4j-movies-template
- https://medium.com/elements/diving-into-graphql-and-neo4j-with-python-244ec39ddd94
- https://github.com/elementsinteractive/flask-graphql-neo4j
- https://gist.github.com/taiwotman/72d23977fd60ad5b017f43b33b42810d
- https://www.youtube.com/watch?v=1JLs166lPcA&list=PL9Hl4pk2FsvV_ojblDzXCg6gxdv437PGg
- https://dev.to/adamcowley/building-a-real-time-ui-on-top-of-neo4j-with-vue-js-and-kafka-152c
On graphql
Check these resources if you don't know what is this graphql thing.
- https://www.howtographql.com/, a very good intro to graphql
- https://dev.to/bogdanned/the-graph-in-graphql-1l99, an in-depth article about the graphql specifications
- https://www.apollographql.com/blog/graphql-explained-5844742f195e/
On neo4j
- I'm using neo4j version 3.5 from the docker images, for no reason in particular apart that I've used it before. I may update to 4.x in the future, if I find reasons to do so.
Modeling
First approach: Don't change anything
The dataset contains informations about perpetrators, victims, violence events and event locations. We will develop models around these concepts, and we will stablish relationships between them afterwards.
First we will extend the GraphObject used in py2neo to adapt it to our needs.
class BaseModel(GraphObject):
"""Extends the GraphObject class with utility methods"""
def __init__(self, **kwargs):
for key, value in kwargs.items():
if hasattr(self, key):
setattr(self, key, value)
@classmethod
def all(cls):
return cls.match(graph)
def as_dict(self):
return dict(self.__node__)
def fetch(self):
pk = getattr(self, "__primarykey__")
return self.match(graph, getattr(self, pk)).first()
def fetch_by_attr(self, attr, value, exact=True):
# https://py2neo.org/v4/ogm.html#object-matching
operator = "=" if exact else "=~"
q = f"_.{attr} {operator} '{value}'" # e.g. _.name =~ ".*K.*" noqa
return list(self.match(graph).where(q))
Concepts (or Nodes)
Perpetrators
Let's start with the Perpetrator model, the easiest. From the codebook we see that they have the following properties
perpetrator_affiliation, stringperpetrator_affiliation_detail, stringwar_tribunal, boolean
This is easily implemented as
class Perpetrator(BaseModel):
perpetrator_affiliation = Property()
perpetrator_affiliation_detail = Property()
war_tribunal = Property()
Victims
individual_id, integergroup_id, intfirst_name, stringlast_name, stringage, string: (this is to support NAs in the data, but they should be handled better e.g. with native nulls in neo4j, I agree. See https://stackoverflow.com/questions/40788440/neo4j-use-merge-with-null-values)minor, booleanmale, booleannumber_previous_arrests, string (same as inage)occupation, stringoccupation_detail, stringvictim_affiliation, stringvictim_affiliation_detail, stringtargeted, string
class Location(BaseModel):
exact_coordinates = Property()
location = Property()
place = Property()
location_order = Property()
latitude = Property()
longitude = Property()
ViolentEvent
Assuming each row describes a violent event, we say that a ViolentEvent develops in different locations specified by the location_n attribute.
A ViolentEvent has thus the following node properties:
violence, stringmethod, stringinterrogation, booleantorture, booleanmistreatment, booleanpress, booleanstart_date_daily, date or stringend_date_daily, date or stringstart_date_monthly, date or stringend_date_monthly, date or string
There are up to 6 locations per event, according to the codebook. We will associate a violent event to a series of locations, like
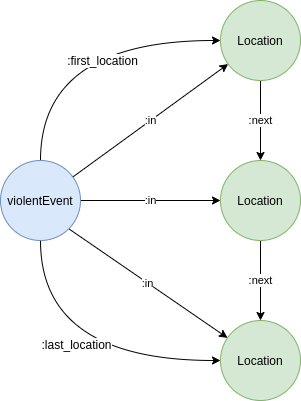
series of locations associated to one violent event
Where location_n describes the n-th location from a series of events. From the codebook, we observe that
exact_coordinates_n: We matched the event sites with coordinates of latitude and longitude. As the report does not have the precise location of all events, we used the closest reference available. This is a dummy variable stating whether coordinates are precise (street level) or not. 1 = yes. There are six variables in the dataset, each pertaining to one location where the individual was found or taken to.location_n: Where the individual was seen or found. There are up to 6 locations, so we coded them as location_1 to location_6 . The same pattern repeats in the variables below. The compilation of the location_n variable was based completely on information given in the Truth Report. However, since this information was in a string format (e.g. intersection of Calle Grecia and Avenida Rosa), creating a new variable incorporating each location’s latitude and longitude was necessary to pursue further analysis of the trends in deaths and disappearances. The format chosen was decimal coordinates.place_n: Place where the individual was spotted/reported to be seen. (in chronological order, from 1 to 6 places). - Categories: Home; Work; University; In custody; In public; In hospital; Unknown
These locations look like this in the original dataset
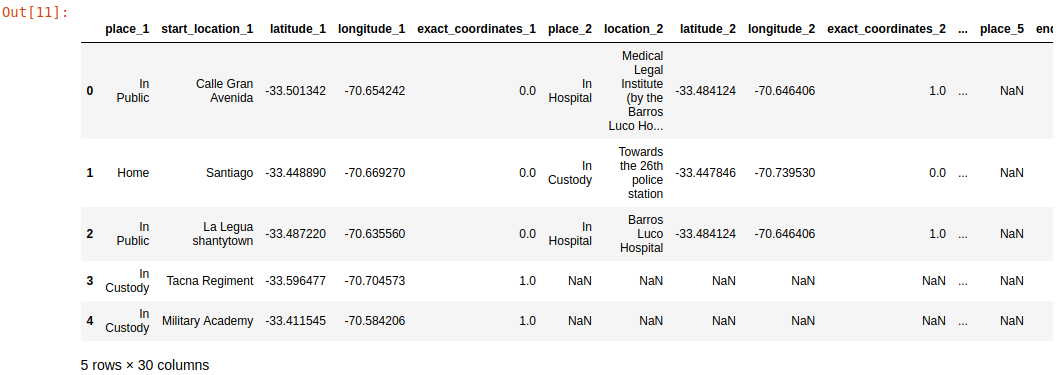
head of the dataset, slicing on the location related attributes
More on modeling series of events
- https://markhneedham.com/blog/2013/11/29/neo4j-modelling-series-of-events/
- https://snowplowanalytics.com/blog/2018/03/26/building-a-model-for-atomic-event-data-as-a-graph/
- https://neo4j.com/news/relationship-thing-saving-evaluating-network-paths-neo4j/
Relationships
We link nodes using RelatedTo and RelatedFrom from py2neo's API. For example, we can link Location and ViolentEvent as follows
class Location(BaseModel):
# properties omitted
# outgoing relationships
next_location = RelatedTo("Location", "NEXT_LOCATION")
# incoming relationships
previous_locations = RelatedFrom("Location", "NEXT_LOCATION")
first_violent_events = RelatedFrom("ViolentEvent", "FIRST_LOCATION")
in_violent_events = RelatedFrom("ViolentEvent", "IN_LOCATION")
last_violent_events = RelatedFrom("ViolentEvent", "LAST_LOCATION")
class ViolentEvent(BaseModel):
# properties omitted
# outgoing relationships
first_location = RelatedTo("Location", "FIRST_LOCATION")
in_location = RelatedTo("Location", "IN_LOCATION")
last_location = RelatedTo("Location", "LAST_LOCATION")
# incoming relationships
victims = RelatedFrom("Victim", "VICTIM_OF")
perpetrators = RelatedFrom("perpetrator", "PERPETRATOR_OF")
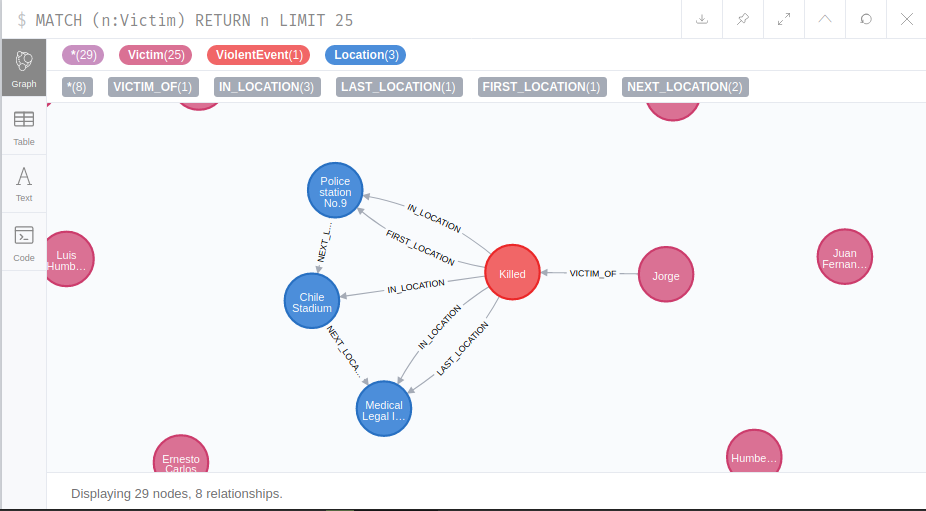
From the rules mentioned above, we end up with a graph that has this shape
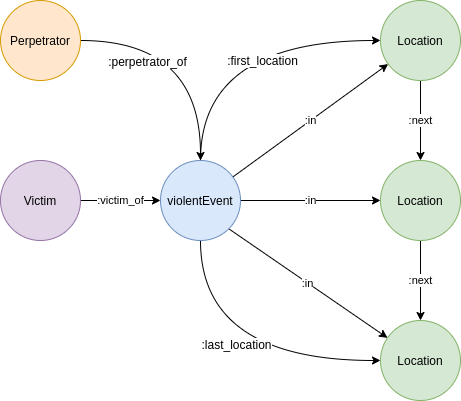
shape of the final graph
Polishing things
The first approach is a bit flaky. We observe that we don't have a proper id or primary keys. These are not explicitly provided in the dataset, so we have to either create them artificially or pick one attribute from each node that will act as one. We can observe how this affects our final graph if we query entities with the same attributes.
Take for example all the locations that refer to La Legua, a Población or shantytown in the south of Santiago that has a powerful history of struggle linked to political conflicts and lately to drug trafficking and crime, as in the words of Rodrigo Ganter (2007, in spanish only).
La Legua has likely consolidated as a recognizable entity within the urban weave of Santiago because of the superposition of segregation, political conflicts and a disciplined culture. The structure of its community and its culture have been what have marked its boundaries with precision, rather than its spatial reality

La Legua is known for being one of the places that presented resistance from the first day to the militar strike, which along with its history made it a target during the regime. In our graph database, we can observe the nodes that represent this location:
$ MATCH (n:Location) where n.location =~ '.*Legua.*' return n LIMIT 5
╒══════════════════════════════════════════════════════════════════════╕
│"n" │
╞══════════════════════════════════════════════════════════════════════╡
│{"location":"La Legua shantytown","place":"In Public","location_order"│
│:"1","latitude":"-33.48722","longitude":"-70.63556"} │
├──────────────────────────────────────────────────────────────────────┤
│{"location":"La Legua shantytown","place":"In Public","location_order"│
│:"1","latitude":"-33.48722","longitude":"-70.63556"} │
├──────────────────────────────────────────────────────────────────────┤
│{"location":"La Legua shantytown","place":"In Public","location_order"│
│:"1","latitude":"-33.48722","longitude":"-70.63556"} │
├──────────────────────────────────────────────────────────────────────┤
│{"location":"La Legua shantytown","place":"In Public","location_order"│
│:"1","latitude":"-33.48722","longitude":"-70.63556"} │
├──────────────────────────────────────────────────────────────────────┤
│{"location":"La Legua shantytown","place":"In Public","location_order"│
│:"1","latitude":"-33.48722","longitude":"-70.63556"} │
└──────────────────────────────────────────────────────────────────────┘
We observe that although these are different nodes, they have the same attributes. The problem here is that we are loading repeated nodes in our database. We want to resolve these entities as equivalent at insertion time, to merge them into one single node.
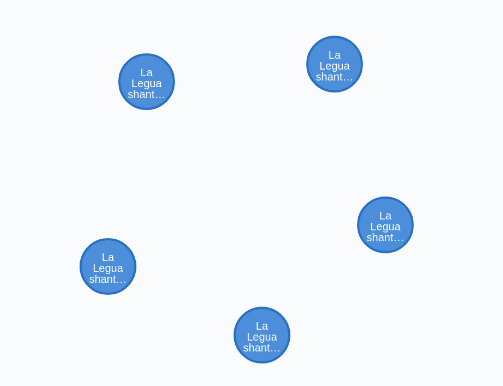
Five nodes representing the same thing. We can merge them into one node.
From the py2neo documentation, we could achieve this by using an existing attribute, like
class Location(BaseModel):
__primarykey__ = "location" # the name of the location
# rest of model below
But we will soon realize that we may be ignoring those locations that have equal location attribute but are different in other attributes. Take for instance the following query:
MATCH (n:Location) where n.location =~ '.*Legua.*' return n.location, n.exact_location, n.place, n.latitude, n.longitude, n.location_order LIMIT 25
╒═════════════════════╤══════════════════╤═══════════╤════════════╤═════════════╤══════════════════╕
│"n.location" │"n.exact_location"│"n.place" │"n.latitude"│"n.longitude"│"n.location_order"│
╞═════════════════════╪══════════════════╪═══════════╪════════════╪═════════════╪══════════════════╡
│"La Legua shantytown"│null │"In Public"│"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"In Public"│"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"In Public"│"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"In Public"│"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"In Public"│"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"In Public"│"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"Home" │"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"Home" │"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"In Public"│"-33.48722" │"-70.63556" │"1" │
├─────────────────────┼──────────────────┼───────────┼────────────┼─────────────┼──────────────────┤
│"La Legua shantytown"│null │"Home" │"-33.48722" │"-70.63556" │"1" │
└─────────────────────┴──────────────────┴───────────┴────────────┴─────────────┴──────────────────┘
We see that although these nodes share the same latitude and longitude, some events occured In public where as other events occured at the victim's home.
In order to resolve this, we will hash these attributes and use the result as a key to avoid redundant data. In other words, we will use and MD5 hash function from python's hashlib
>>> hashlib.md5(b"foo").hexdigest()
'acbd18db4cc2f85cedef654fccc4a4d8'
In code, this would be something like
import hashlib
import typing as T
def to_md5(elements: T.List[str], *args, **kwargs) -> str:
"""calculates the MD5 hash of the string of concatenated elements"""
pre = "".join(str(x).lower() for x in elements)
return hashlib.md5(pre.encode("utf-8")).hexdigest()
I'm not thinking too much into this: I will produce at least 2398 different keys, and considering this is not for cryptographic purposes, MD5 gives me plenty of room for that.
For tables and graphs that are intended to grow over time, you should think more about using this approach, for many reasons. MD5 is full of holes, it's not secure for cryptographic purposes like storing passwords (its initial purpose), and it has known hash collision issues.
For the case of Perpetrator we note that from 2398 total instances in the db, we have these unique entities:
$ MATCH (n:Perpetrator) RETURN COUNT(DISTINCT n.perpetrator_affiliation_detail)
228
$ MATCH (n:Perpetrator) RETURN COUNT(DISTINCT n.perpetrator_affiliation)
3
$ MATCH (n:Perpetrator) RETURN COUNT(DISTINCT n.war_tribunal)
2
We can create 228*3*2 = 1392 unique ids if we concatenate attribute values. We can compress this index to have some meaning, like a hash of (attr1 + attr2 + attr3). As it is, Perpetrator is sort of a junk dimension in the Data Warehousing jargon.
class Perpetrator(BaseModel):
__primarykey__ = "perpetrator_id"
perpetrator_id = Property()
# rest of model below
For the case of ViolentEvents it is more difficult. We also have 2398 instances, but how do we tell them apart? Let's have a look at the dates, which seem promising as primary keys.
MATCH (n:ViolentEvent) RETURN COUNT(DISTINCT n.start_date_daily), COUNT(DISTINCT n.end_date_daily), COUNT(DISTINCT n.start_date_monthly), COUNT(DISTINCT n.end_date_monthly)
╒═════════╤═════════╤═════════╤═════════╕
│"count(di│"count(di│"count(di│"count(di│
│stinct n.│stinct n.│stinct n.│stinct n.│
│start_dat│end_date_│start_dat│end_date_│
│e_daily)"│daily)" │e_monthly│monthly)"│
│ │ │)" │ │
╞═════════╪═════════╪═════════╪═════════╡
│652 │658 │151 │155 │
└─────────┴─────────┴─────────┴─────────┘
The main difficulty is with the data as we have it right now, we have no way to know that two nodes refer to the same event. We will assume that all instances in this table are unique i.e. all violent events are unique, and we will give them a UUID accordingly.
class ViolentEvent(BaseModel):
__primarykey__ = "event_uuid"
event_uuid = Property()
# rest of model goes here
With these keys in place, we start over and recreate the graph. We check for locations referring to La Legua, and see that now there are three instances in total. We removed a lot of redundant data this way!
MATCH (n:Location) where n.location =~ '.*Legua.*' return n LIMIT 25
╒══════════════════════════════════════════════════════════════════════╕
│"n" │
╞══════════════════════════════════════════════════════════════════════╡
│{"location":"La Legua shantytown","place":"In Public","location_order"│
│:"1","location_id":"cb95da6b208a47984cb25051d4ec9561","latitude":"-33.│
│48722","longitude":"-70.63556"} │
├──────────────────────────────────────────────────────────────────────┤
│{"location":"La Legua","place":"In Public","location_order":"1","locat│
│ion_id":"a25c89cb84f42e76be3c60c34d536abd","latitude":"-33.48722","lon│
│gitude":"-70.63556"} │
├──────────────────────────────────────────────────────────────────────┤
│{"location":"La Legua shantytown","place":"Home","location_order":"1",│
│"location_id":"8a0bf7de20dd6ed6c3f76aab95d942bb","latitude":"-33.48722│
│","longitude":"-70.63556"} │
└──────────────────────────────────────────────────────────────────────┘
In the same way, we see that
$ MATCH (n:Perpetrator) RETURN COUNT(DISTINCT n)
244
Loading the dataset into a graph
We are loading the dataset with one script, it's long so please bear with me. You can check the full script in github
import os
import csv
import typing as T
from py2neo import Graph
graph = Graph(
host=os.environ.get("NEO4J_HOST"),
port=os.environ.get("NEO4J_PORT"),
user=os.environ.get("NEO4J_USER"),
password=os.environ.get("NEO4J_PASSWORD"),
)
def clear_graph():
return graph.run("MATCH (n) DETACH DELETE n").stats()
def __create_node(graph_object, dry_run=False):
current_app.logger.debug(f"Creating {graph_object}")
graph.create(graph_object)
current_app.logger.debug("Done")
def get_locations(row: dict) -> T.List[Location]:
"""Parses the locations in the dataset into an ordered collection of Location instances"""
locations = []
# there are 6 locations max in the dataset
for n in range(1, 7):
# We will fetch those that are not empty or not "NA"
location_name = row.get(f"location_{n}", None)
if location_name is not None and location_name != "NA":
loc_mapping = {
"exact_location": row[f"exact_coordinates_{n}"],
"location": location_name,
"place": row[f"place_{n}"],
"latitude": row[f"latitude_{n}"],
"longitude": row[f"longitude_{n}"],
"location_order": n,
}
# instance of Location, using the MD5 hash of attributes as ID
loc = Location(
location_id=to_md5(loc_mapping.values()),
**loc_mapping
)
locations.append(loc)
return locations
def seed_graph(filepath, **kwargs):
with open(filepath) as fp:
csv_reader = csv.DictReader(f=fp)
for row in csv_reader:
# create victims
victim = Victim(
individual_id=row["individual_id"], # pk
group_id=row["group_id"],
first_name=row["first_name"],
last_name=row["last_name"],
age=row["age"],
minor=row["minor"],
male=row["male"],
nationality=row["nationality"],
number_previous_arrests=row["number_previous_arrests"],
occupation=row["occupation"],
occupation_detail=row["occupation_detail"],
victim_affiliation=row["victim_affiliation"],
victim_affiliation_detail=row["victim_affiliation_detail"],
targeted=row["targeted"],
)
perp_mapping = {
"perpetrator_affiliation": row["perpetrator_affiliation"],
"perpetrator_affiliation_detail": row[
"perpetrator_affiliation_detail"
],
"war_tribunal": row["war_tribunal"],
}
# obtain the md5 as PK
perp = Perpetrator(
perpetrator_id=to_md5(perp_mapping.values()), **perp_mapping
)
locations = get_locations(row)
event = ViolentEvent(
event_id=str(uuid.uuid4()), # pk
violence=row["violence"],
method=row["method"],
interrogation=row["interrogation"],
torture=row["torture"],
mistreatment=row["mistreatment"],
press=row["press"],
start_date_daily=row["start_date_daily"],
end_date_daily=row["end_date_daily"],
start_date_monthly=row["start_date_monthly"],
end_date_monthly=row["end_date_monthly"],
page=row["page"],
additional_comments=row["additional_comments"],
)
# create relationships between event and locations
if locations:
event.first_location.add(locations[0])
event.last_location.add(locations[-1])
for index, location in enumerate(locations):
event.in_location.add(location)
if index != 0:
locations[index - 1].next_location.add(location)
victim.victim_of.add(event)
perp.perpetrator_of.add(event)
# create nodes
__create_node(victim, dry_run)
__create_node(perp, dry_run)
__create_node(event, dry_run)
for location in locations:
__create_node(location, dry_run)
We could have done something using Cypher and APOC, a library for many kinds of tasks within neo4j. At some point though, Cypher's capabilities fell short so I had to rely on python.
After we've done this, we can start querying the graph with things like
General statistics
from https://neo4j.com/developer/kb/how-do-i-produce-an-inventory-of-statistics-on-nodes-relationships-properties/ we can create an inventory of miscellaneous statistics of the graph.
MATCH (n)
WITH labels(n) as labels, size(keys(n)) as props, size((n)--()) as degree
RETURN
DISTINCT labels,
count(*) AS NumofNodes,
avg(props) AS AvgNumOfPropPerNode,
min(props) AS MinNumPropPerNode,
max(props) AS MaxNumPropPerNode,
avg(degree) AS AvgNumOfRelationships,
min(degree) AS MinNumOfRelationships,
max(degree) AS MaxNumOfRelationships
╒════════╤════════╤════════╤════════╤════════╤════════╤════════╤════════╕
│"labels"│"NumofNo│"AvgNumO│"MinNumP│"MaxNumP│"AvgNumO│"MinNumO│"MaxNumO│
│ │des" │fPropPer│ropPerNo│ropPerNo│fRelatio│fRelatio│fRelatio│
│ │ │Node" │de" │de" │nships" │nships" │nships" │
╞════════╪════════╪════════╪════════╪════════╪════════╪════════╪════════╡
│["Victim│2398 │13.0 │13 │13 │1.0 │1 │1 │
│"] │ │ │ │ │ │ │ │
├────────┼────────┼────────┼────────┼────────┼────────┼────────┼────────┤
│["Violen│2398 │13.0 │13 │13 │4.690992│1 │9 │
│tEvent"]│ │ │ │ │49374478│ │ │
│ │ │ │ │ │1 │ │ │
├────────┼────────┼────────┼────────┼────────┼────────┼────────┼────────┤
│["Locati│1841 │6.0 │6 │6 │5.652906│2 │227 │
│on"] │ │ │ │ │02933188│ │ │
│ │ │ │ │ │8 │ │ │
├────────┼────────┼────────┼────────┼────────┼────────┼────────┼────────┤
│["Perpet│244 │4.0 │4 │4 │1.0 │1 │1 │
│rator"] │ │ │ │ │ │ │ │
└────────┴────────┴────────┴────────┴────────┴────────┴────────┴────────┘
We observe right away that on average, a violent event is linked to ~4.7 nodes. We would like to be more specific, and for this we will craft the subgraph that we would like to match, and then we will get the outgoing degree of the event for all victims.
This is equivalent to asking for the length on average of the paths walked for a victim. This boils down to fetch the initial and the last location of each event, and count how many locations are in the path formed by those locations.
match (v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)
with e
match pathA=(fl:Location)<-[:FIRST_LOCATION]-(e)-[:LAST_LOCATION]->(ll:Location)
with fl, ll
match pathB=(fl)-[:NEXT_LOCATION*]->(ll)
with length(pathB) as pathLength
return avg(pathLength)
╒══════════════════╕
│"avg(pathLength)" │
╞══════════════════╡
│1.4383708467309761│
└──────────────────┘
In other words, a victim visits ~1.44 places on average before ending its journey (either by getting killed, dissapeared, or suicide, for example).
This is the same as above, but with substracting -2 to the length because this path contains the event twice each time
match (e:ViolentEvent)
with e
match path=(e)-[:FIRST_LOCATION]->(fl:Location)-[:NEXT_LOCATION*]->(ll:Location)<-[:LAST_LOCATION]-(e)
with length(path) - 2 as pathSize
return avg(pathSize)
╒══════════════════╕
│"avg(pathSize)" │
╞══════════════════╡
│1.4383708467309761│
└──────────────────┘
Using the geospatial module of neo4j
From https://neo4j.com/docs/cypher-manual/3.5/functions/spatial/, we could update relationships with their geodesic distance. For now we just want to see it.
MATCH (v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)
WITH e
MATCH pathA=(fl:Location)<-[:FIRST_LOCATION]-(e)-[:LAST_LOCATION]->(ll:Location)
WITH fl, ll
MATCH pathB=(fl)-[:NEXT_LOCATION*]->(ll)
WITH point({x: toFloat(fl.longitude) , y: toFloat(fl.latitude), crs:'wgs-84'}) as p1, point({x: toFloat(ll.longitude), y: toFloat(ll.latitude), crs:'wgs-84'}) as p2, fl, ll
RETURN fl.location, ll.location, distance(p1, p2)
LIMIT 5
╒═══════════════════╤═══════════════════╤══════════════════╕
│"fl.location" │"ll.location" │"distance(p1, p2)"│
╞═══════════════════╪═══════════════════╪══════════════════╡
│"Ochagavia Bridge o│"Ochagavia Bridge o│0.0 │
│ver Callejón Lo Ova│ver Callejón Lo Ova│ │
│lle" │lle" │ │
├───────────────────┼───────────────────┼──────────────────┤
│"Intersection of Lo│"On route to Barros│7058.819005808001 │
│ Sierra and Lo Espe│ Lucas Hospital " │ │
│jo" │ │ │
├───────────────────┼───────────────────┼──────────────────┤
│"downtown Santiago"│"Villa Grimaldi" │12154.56171338133 │
├───────────────────┼───────────────────┼──────────────────┤
│"downtown Santiago"│"Villa Grimaldi" │12154.56171338133 │
├───────────────────┼───────────────────┼──────────────────┤
│"Calle Nuble, 1034"│"Central Emergency │2995.4570977906865│
│ │Clinic" │ │
└───────────────────┴───────────────────┴──────────────────┘
From the second result, we can check with google maps that the distance approximatedly 9 kilometers
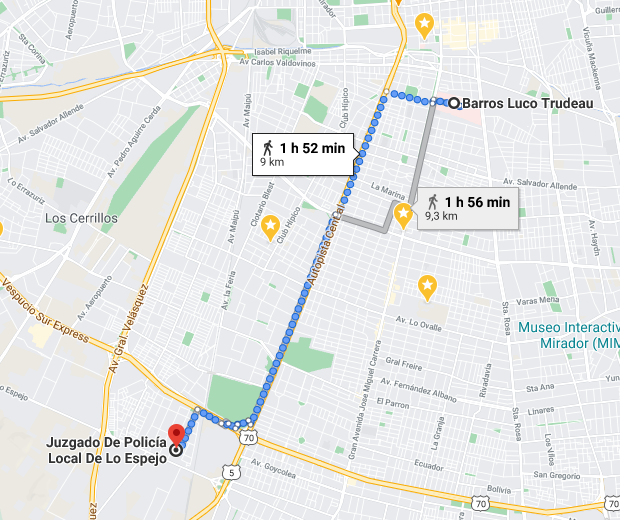
From "Ñuble 1034" to the "Central Emergency Clinic" it's a 3 km distance, approximately.
Which type of events are linked to more locations?
MATCH (v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)
WITH e
MATCH path=(e)-[r:IN_LOCATION]->(l:Location)
RETURN e.violence, count(l) AS degree
ORDER BY degree DESC
╒═════════════════════════════════════╤════════╕
│"e.violence" │"degree"│
╞═════════════════════════════════════╪════════╡
│"Killed" │2331 │
├─────────────────────────────────────┼────────┤
│"Disappearance" │1438 │
├─────────────────────────────────────┼────────┤
│"Disappearance, Information of Death"│212 │
├─────────────────────────────────────┼────────┤
│"Unresolved" │86 │
├─────────────────────────────────────┼────────┤
│"Suicide" │16 │
├─────────────────────────────────────┼────────┤
│"NA" │2 │
└─────────────────────────────────────┴────────┘
If we analyze the average number of locations, we get a different perspective
MATCH (v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)
WITH e
MATCH path=(e)-[r:IN_LOCATION]->(l:Location)
WITH e, count(l) as degree
RETURN e.violence, avg(degree) AS avgDegree
ORDER BY avgDegree DESC
╒═════════════════════════════════════╤══════════════════╕
│"e.violence" │"avgDegree" │
╞═════════════════════════════════════╪══════════════════╡
│"Suicide" │2.0 │
├─────────────────────────────────────┼──────────────────┤
│"NA" │2.0 │
├─────────────────────────────────────┼──────────────────┤
│"Disappearance, Information of Death"│1.9629629629629628│
├─────────────────────────────────────┼──────────────────┤
│"Killed" │1.8618210862619833│
├─────────────────────────────────────┼──────────────────┤
│"Disappearance" │1.7388149939540511│
├─────────────────────────────────────┼──────────────────┤
│"Unresolved" │1.3230769230769233│
└─────────────────────────────────────┴──────────────────┘
On average, people that died because of suicide visited more locations than those that were killed or dissapeared. It's hard to consider this fact as final, since there is that "NA" messing with the data.
Longest paths
We want to know about those victims that moved the most, i.e. have the longest trajectories. We can do so with
MATCH (v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)
WITH v, e
MATCH pathA=(fl:Location)<-[:FIRST_LOCATION]-(e)-[:LAST_LOCATION]->(ll:Location)
WITH v, e, fl, ll
MATCH pathB=(fl)-[:NEXT_LOCATION*]->(ll)
WITH v, e, pathB, length(pathB) as pathLength
RETURN v, e, pathB
ORDER BY pathLength DESC
LIMIT 1
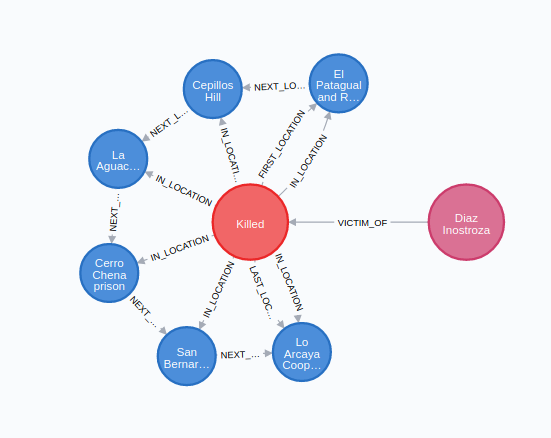
This result corresponds to Jose Manuel Díaz Inostroza, a 29 years old farm worker that was tortured and killed after one month since he was taken, along with other four people.
Number of people linked to a location
MATCH (v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)-[:IN_LOCATION]->(l:Location)
return l.location, count(v) as victimCount
order by victimCount desc
limit 10
╒════════════════════════════════╤═════════════╕
│"l.location" │"victimCount"│
╞════════════════════════════════╪═════════════╡
│"Villa Grimaldi" │109 │
├────────────────────────────────┼─────────────┤
│"Santiago" │107 │
├────────────────────────────────┼─────────────┤
│"Medical Legal Institue" │74 │
├────────────────────────────────┼─────────────┤
│"Londres No.38" │56 │
├────────────────────────────────┼─────────────┤
│"Cuatro Alamos" │55 │
├────────────────────────────────┼─────────────┤
│"Medical Legal Institute" │49 │
├────────────────────────────────┼─────────────┤
│"San Bernardo Infantry Regiment"│49 │
├────────────────────────────────┼─────────────┤
│"Paine substation" │36 │
├────────────────────────────────┼─────────────┤
│"La Moneda Palace" │36 │
├────────────────────────────────┼─────────────┤
│"Chile Stadium" │32 │
└────────────────────────────────┴─────────────┘
Londres 38
We observe that Londres 38 appears in the list, a known place in the center of Santiago that acted as a clandestine detention center from 1973 to 1975, and is currently open to the community, acting as a memorial center (my rough translation).
There is an active group of people working on researching and exposing the activities that happened in this place, you can read more about them here (in spanish only).
From the graph, we can fetch the names of the victims that passed at some point by Londres 38.
MATCH p=(v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)-[:IN_LOCATION]->(l:Location)
where l.location =~ ".*Londres.*"
return p
It is hard to represent all the names visually in one screenshot, and this is the best I could do for now.
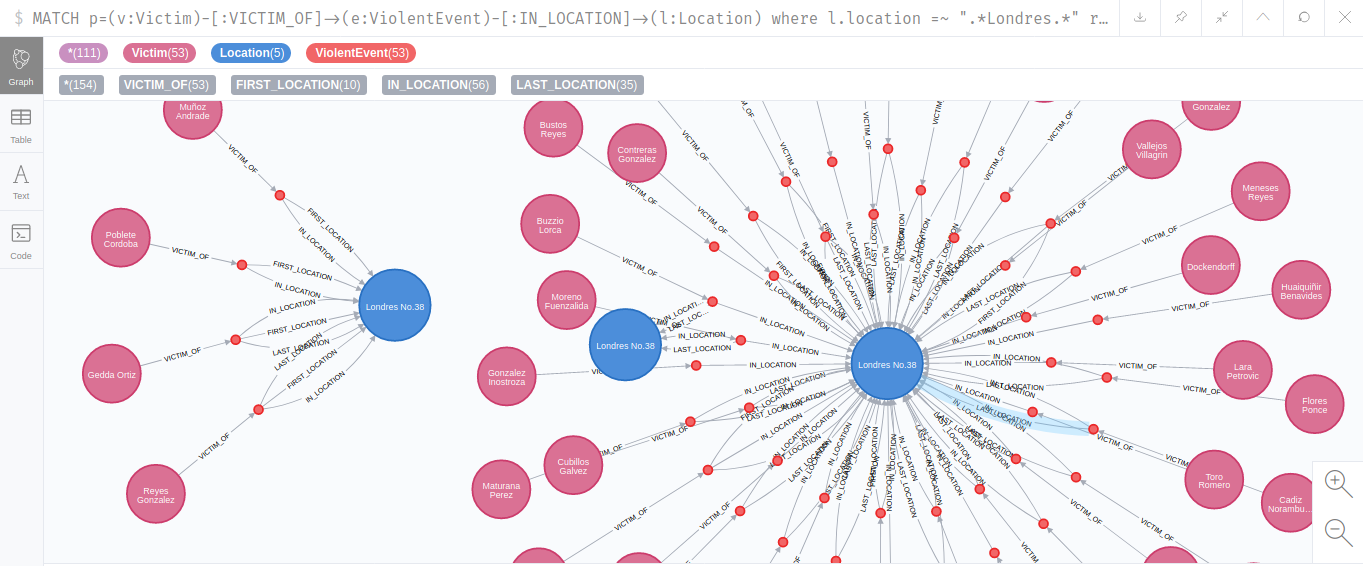
We can get the list of names with Cypher directly
MATCH p=(v:Victim)-[:VICTIM_OF]->(e:ViolentEvent)-[:IN_LOCATION]->(l:Location)
where l.location =~ ".*Londres.*"
return l.location, v.first_name, v.last_name
╒═══════════════╤═══════════════════════╤═══════════════════════╕
│"l.location" │"v.first_name" │"v.last_name" │
╞═══════════════╪═══════════════════════╪═══════════════════════╡
│"Londres No.38"│"Gregorio Antonio" │"Gaete Farias" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Rodolfo Alejandro" │"Espejo Gomez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Bautista" │"Maturana Perez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Washington Hernán" │"Maturana Perez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Eduardo Enrique" │"Lara Petrovic" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Enrique Segundo" │"Toro Romero" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"María Elena" │"Gonzalez Inostroza" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Hernán Galo" │"Gonzalez Inostroza" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Alvaro Miguel" │"Barrios Duque" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Muriel" │"Dockendorff Navarrete"│
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"María Angélica" │"Andreoli Bravo" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Zacarías Antonio" │"Machuca Muñoz" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Juan Ernesto" │"Ibarra Toledo" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Ramón Osvaldo" │"Nuñez Espinoza" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"José Manuel" │"Ramirez Rosales" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Sergio Daniel" │"Tormen Mendez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Luis Julio" │"Guajardo Zamorano" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Juan Rosendo" │"Chacon Olivares" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Alvaro Modesto" │"Vallejos Villagrin" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Jorge Arturo" │"Grez Aburto" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Carlos Luis" │"Cubillos Galvez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Jorque Enrique" │"Espinoza Mendez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Jaime Mauricio" │"Buzzio Lorca" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Jaime del Tránsito" │"Cadiz Norambuena" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Sergio Arturo" │"Flores Ponce" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Luis Armando" │"Valenzuela Figueroa" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Alfonso René" │"Chanfreau Oyarce" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Newton Larrín" │"Morales Saaverdra" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Carlos Eladio" │"Salcedo Morales" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Sonia de las Mercedes"│"Bustos Reyes" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Joel" │"Huaiquiñir Benavides" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Alejandro Arturo" │"Parada Gonzalez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Segio Sebastían" │"Montecinos Alfaro" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Oscar Manuel" │"Castro Videla" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Juan Aniceto" │"Meneses Reyes" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Germán Rodolfo" │"Moreno Fuenzalida" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Bárbara" │"Uribe Tamblay" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Edwin Francisco" │"Van Jurick Altamirano"│
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Abundio Alejandro" │"Contreras Gonzalez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Marcos Esteban" │"Quiñones Lembach" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Martín" │"Elgueta Pinto" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Leopoldo Daniel" │"Muñoz Andrade" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Pedro Enrique" │"Poblete Cordoba" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Máximo Antonio" │"Gedda Ortiz" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Agustín Eduardo" │"Reyes Gonzalez" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Germán Rodolfo" │"Moreno Fuenzalida" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Jaime Mauricio" │"Buzzio Lorca" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"José Caupolicán" │"Villagra Astudillo" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Arnoldo" │"Laurie Luengo" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Hernán" │"Sarmiento Sabater" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Jorge Alejandro" │"Olivares Graindorge" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"María Ines" │"Alvarado Borgel" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Francisco Javier" │"Fuentealba Fuentealba"│
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Artemio Segundo" │"Gutierrez Avila" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"Daniel Abraham" │"Reyes Piña" │
├───────────────┼───────────────────────┼───────────────────────┤
│"Londres No.38"│"María Ines" │"Alvarado Borgel" │
└───────────────┴───────────────────────┴───────────────────────┘
From the Londres 38 site, we can learn more about some of these persons. For instance, María Ines Alvarado Borgel was taken with 21 years by national security agents (DINA). From the english version of the report (p. 690).
On July 17, 1974, DINA agents arrested the MIR activist María Inés ALVARADO BORGEL in the Providencia district. Her captors later took her to the home of Martín ELGUETA PINTO, who was also arrested along with Juan Rosendo CHACON OLIVARES. These two were active in MIR. Other persons were arrested with them but were later released. During the days after her arrest, her captors took María Inés Alvarado to her family's house several times. All three disappeared from the Londres No. 38 site, where they had been seen by witnesses. The Commission is convinced that the disappearance of these three people was the work of government agents who thus violated their human rights.
The list of the 98 persons known to date that were killed, dissapeared or died after being held captives in Londres 38 is extensively documented in https://www.londres38.cl/1937/w3-propertyvalue-35254.html. The loaded dataset is displaying 58 of them.
Wrapping up
I am stopping now. Thanks for reading until here! You can check the live repository in Github.
We can enrich this graph in many ways, but before start making up requirements, it's better to look at this data using a map. In a future post, we will expose this graph through a graphql service layer, and we will deploy a leaflet map that consumes it.